As someone deeply afflicted with N.A.D.D. (Nerd Attention Deficit Disorder), it can be hard to recall exactly where I saw ThatThing™️. To help me find That Thing™️ later without slowing me down in the moment, I've become an avid user of tools like Notion Links, Quick Notes, and Github Stars to ensure I don't have to dig to find That Thing™️ when I really need it.
This append only log of potential That Thing™️s has grown into the thousands, and covers a range of topics, including impactful gems like Kathy Sierra, The Children's Illustrated Guide to Kubernetes, UnJS Ecosystem, Camaino's Ways, and ShapeUp -to name a few. Despite its treasures, it's contents are randomly distributed, unmaintained, often outdated, biased, and effectively drown anyone whose ever borrowed it. It's not awesome... in it's current form.
Purpose
-
Expose my collection of quality content on my personal site in a useful, automated and cheap way
-
Deep dive into the current state of Semantic Search, Embeddings, Vector Databases and -shivers nervously- Python
-
Form opinions on what parts of this new stack are the most likely to cause pain and suffering at scale
Starting Point
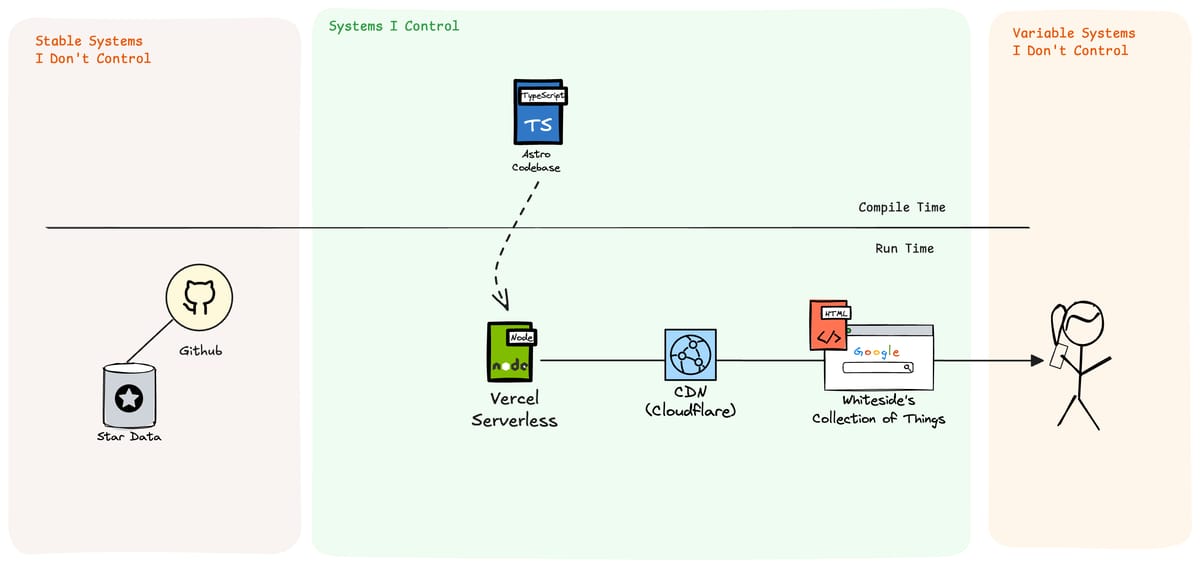
Here's a sketch of how this system currently exists. A system designed to let me write content in markdown, create a few mostly static pages, and efficiently serve that content to any device for less than $5 a month. This system values Cost, Convenience, Usability, and Simplicity and will trade off Functionality, Scale, and Security when all else is equal.
What I Have
- My site is built using Astro in Typescript, which builds into a serverless function and static files which Vercel and Cloudflare distribute to the world for a few pennies a month.
What I Know
-
Github keeps a database of repositories I've starred, and exposes it as REST and GraphQL APIs which are maintained and stable.
-
Readers like you access my site via whatever device you have handy, which vary drastically in every way
What I Need [and how i'll refer to it later]
-
A reliable way to regularly extract and normalize Github data [Github Client]
-
A way of generating embeddings and other AI magic numbers [Enrichment]
-
A way to store the outputs of the Github Client and Enrichment because they are slow and expensive [Data Store]
-
A way to semantically query the [Data Store] at runtime
First Stab
Lots of unknowns here, so first round I aimed for quick, modular, functionality.
-
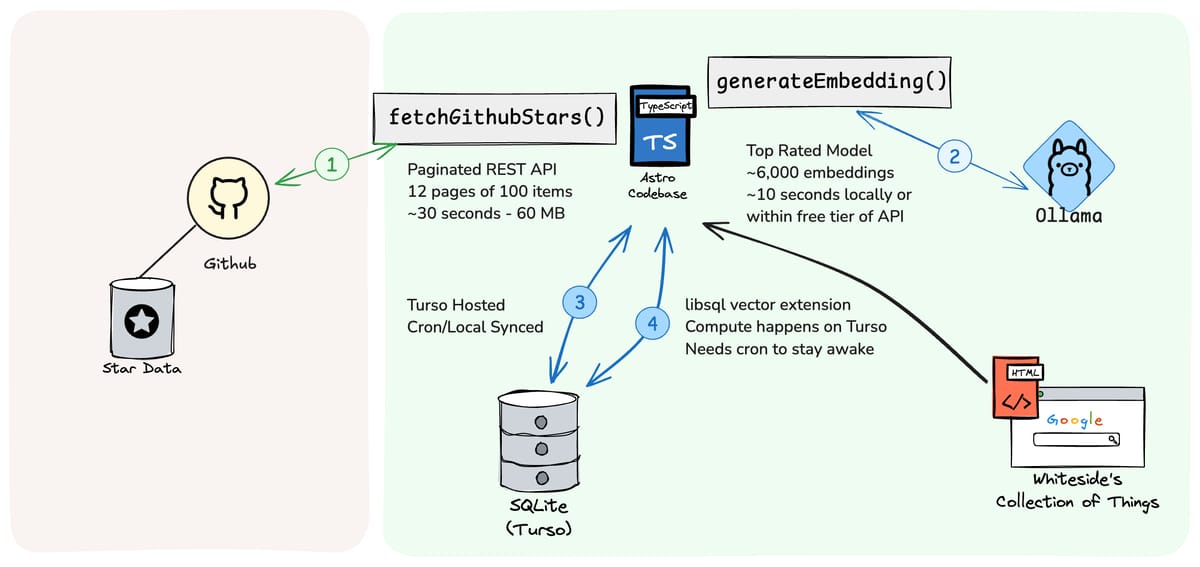
Fetching the github data was as expected, though with rate limits it can be slow and produce enough data to be annoying. I shoved it in a file to avoid loading it every time I made a change.
-
Generating embeddings was also pleasantly uneventful. I had Ollama running on my studio, ran
ollama pull nomic-embed-text, and had a local inference server running with just a few lines. -
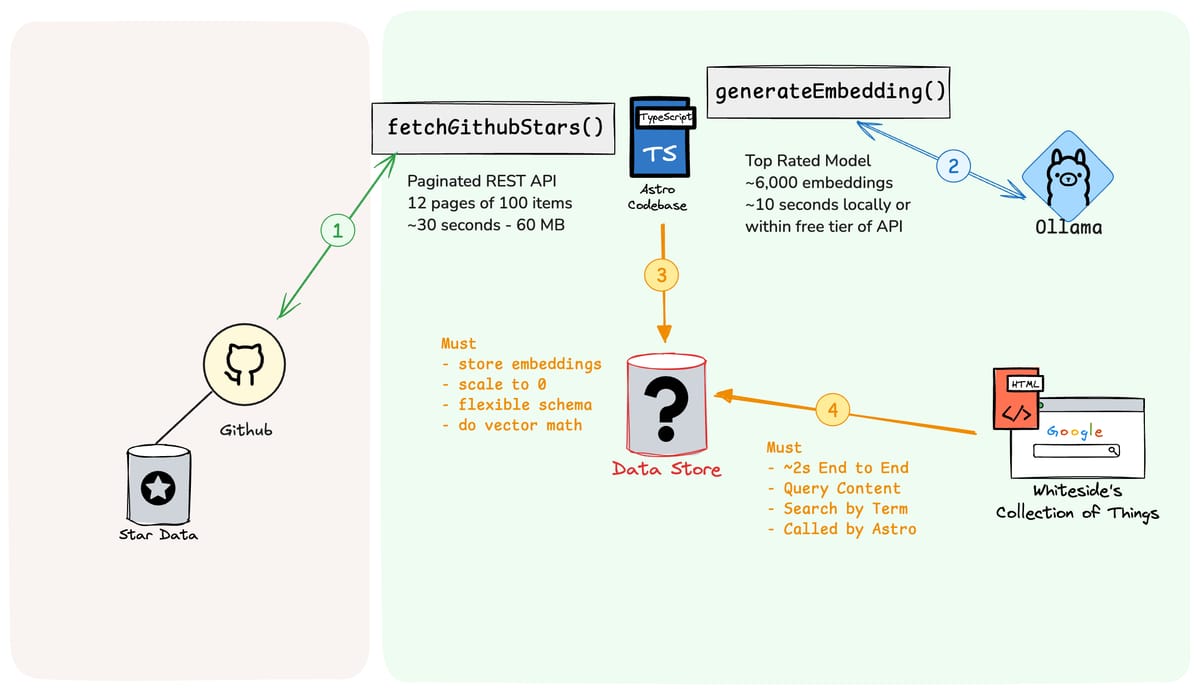
No data store solution came to mind that was quick and easy, so instead I outlined the requirements in the diagram below. Overall it had to support vector math, scale to 0, and have minimal latency when invoked from Astro.
Databases rule everything around me
The two biggest needs are to (a) 'scale to zero' when not in use, and (b) compute vector similarity. Beyond those minimums, I care about developer experience, runtime latency and minimal dependencies. Here are the main contenders:
| "Serverless" Relational | Serverless Vector | Embedded Engine | |
|---|---|---|---|
| Examples | • postgres (Neon) • SQLite (Turso) | • upstash | • LanceDB • DuckDB |
| Developer Experience | Acceptable SQL ORM Tooling | Lacks mature tooling | Apache Arrow Ecosystem |
| Infrastructure | SaaS API or Self Hosted | SaaS API | S3 Bucket |
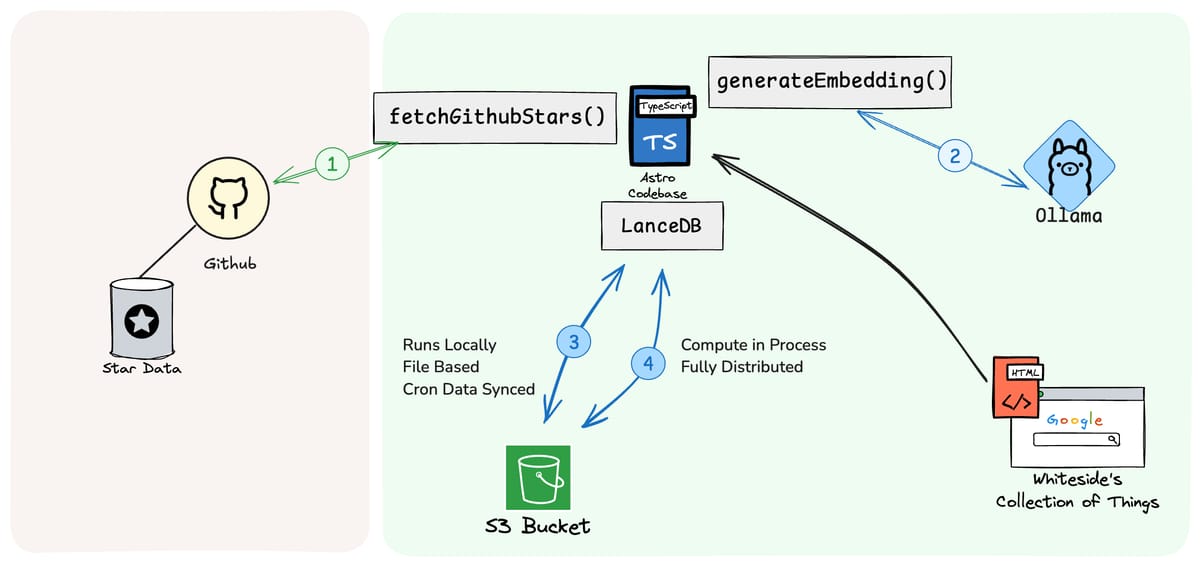
The two most promising options which minimize runtime infrastructure and align with the data model are SQLite and LanceDB. These approaches look very similar both to the developer and on paper, but it would be great to avoid another SaaS API if Lance works out. Here's the updated sketch for LanceDB.
Sketch for SQLite