
While LLMs appear very capable, it's important to remember they have no understanding of what they emit and cannot perform actual reasoning or logic. As a human, we're hard-wired to assign meaning to language. It's hard to fully grok that LLMs are really just predicting the most likely token in the sequence, over and over again.
This post explores a simplified view of how LLMs work to help the concepts feel more intuitive, which is critical for anyone using them in a product. We'll then use this understanding to outline principals for when to use (and avoid) LLMs.
Part 1: Understanding the Stochastic Parrots
A Visual Metaphor
There's a segment from 'The Price is Right' which introduces a game, Plinko. To play Plinko, a disk is dropped from the top of a tall, upright board filled with pegs. As the disk falls, it bounces off the pegs until it lands in one of several slots at the bottom, each with a different prize.
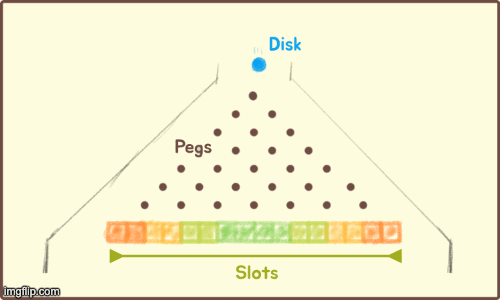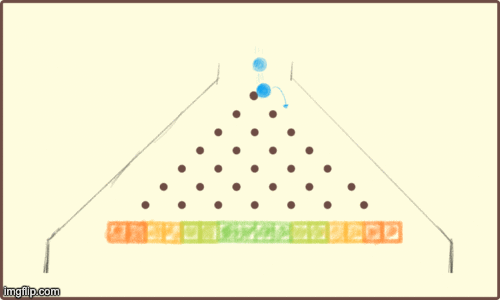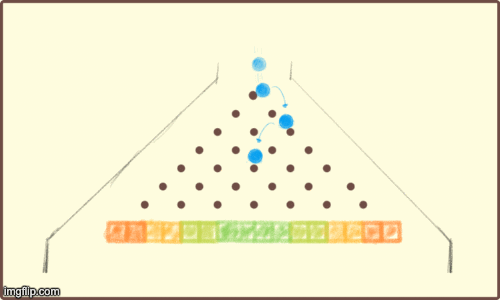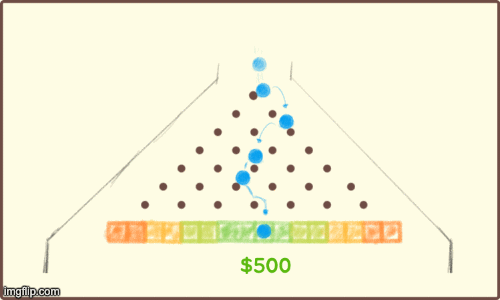
When an LLMs generates a response, the algorithm responsible works in a very similar way. To determine the next token (2-3 characters) in a response, the LLM effectively plays a round of extreme Plinko. Instead of prize money, the winning slot decides which characters (token) to say next.
For example, here's roughly how a 28 parameter (pegs) LLM could "decide" how to respond. Notice that there is some randomness involved, but the pegs heavily influence the result.
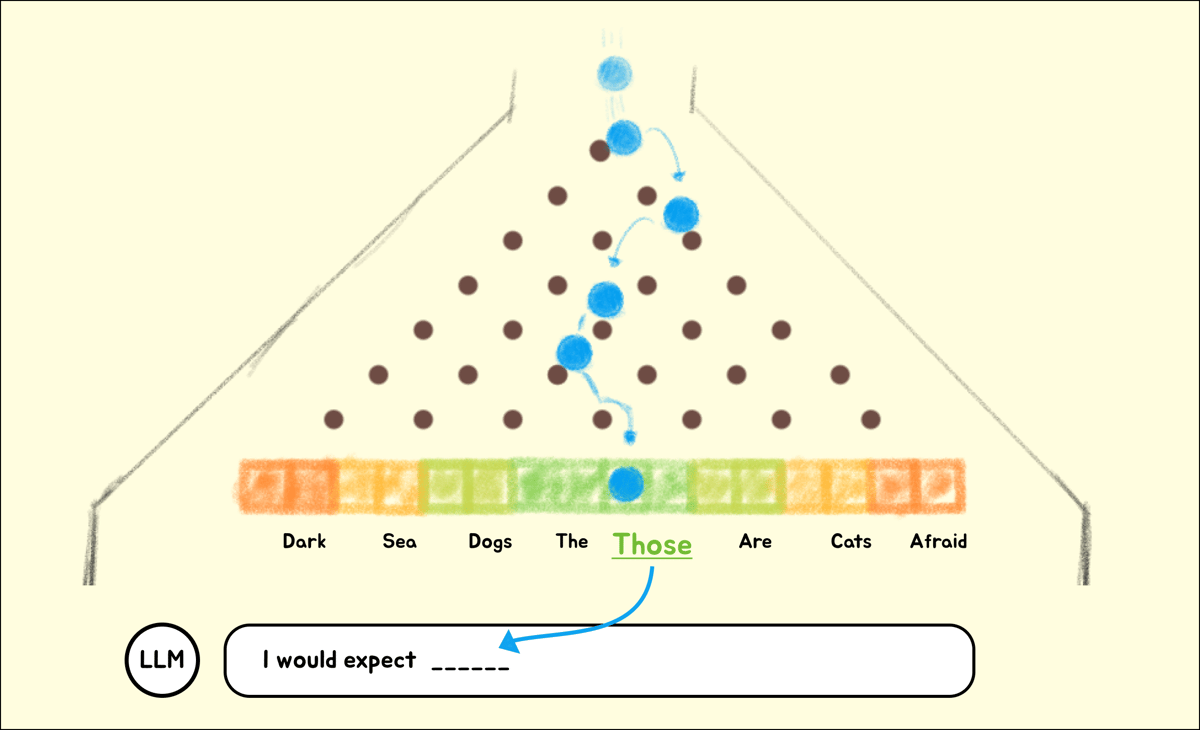
How we influence the probabilities of a model's responses, is by scaling how many parameters (pegs) and modifying each parameter (training).
To train an LLM, we can tune each of the pegs (parameters) on the board to influence the outcomes (token). Parameters are not limited to shape and size, and can vary based on input and previously generated tokens - the sky is the limit. This tuning process is how the machine "learns", and results in parameters beyond human understanding.
Using many examples and a lot of GPU time, we eventually hammer the model into submission determine a set of parameters (pegs) that pass all of our tests. These are a model's weights.
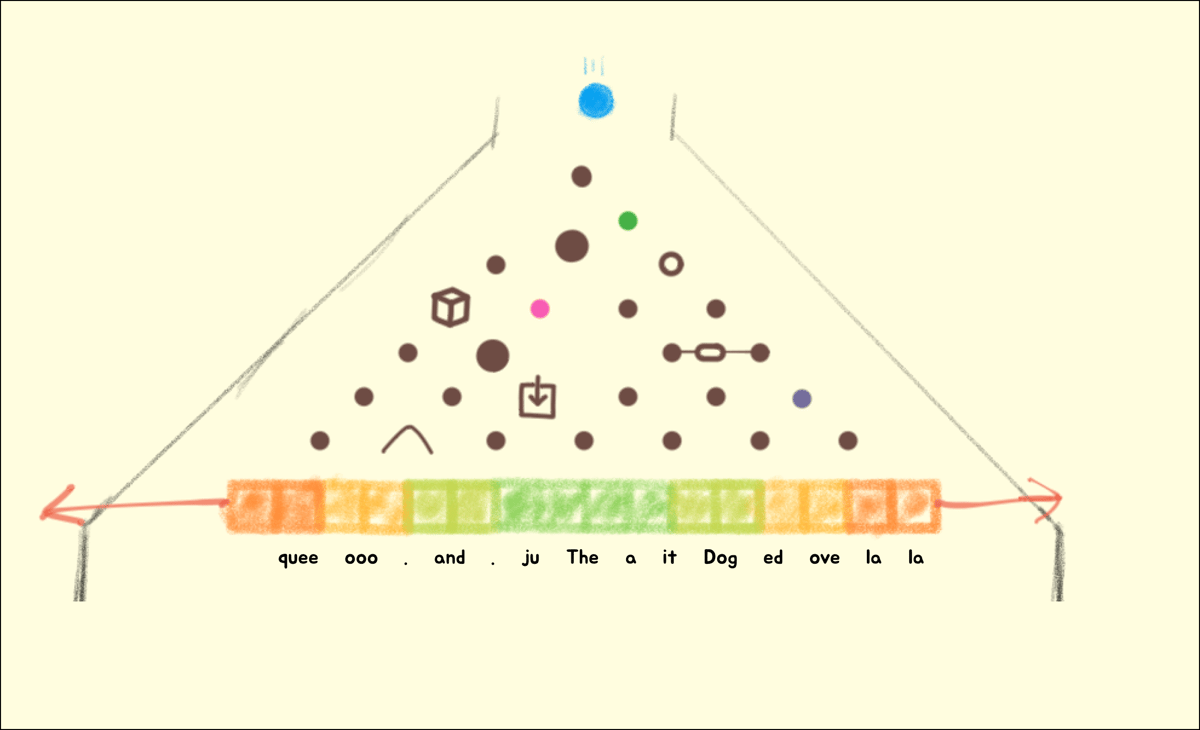
From here, all it takes for this LLM Plinko Player to start quoting Shakespeare is to add more pegs (parameters). 20,000,000,000 more at a minimum. After a month and $20 million of training, you'll have the weights you need (200GB+) to generate sequences of probable characters for any input you want.
While this analogy provides a relatable model of how many LLMs work, every day researchers and engineers are finding clever ways to improve this incredible feat of technology in huge ways. Omissions of key concepts like attention heads, unsupervised learning and transformers is for simplicity and relevance to how I'm recommending we leverage LLMs in this product. Comments/suggestions on making it more accurate without adding complexity are welcome.
Part 2: Deploying LLMs
Armed with this perspective of how LLMs generate responses, we can create some principals to leverage LLMs more strategically in our products, and as crucially, find the risky problems to avoid.
LLM Friendly Problems
To get the most out of your LLM, consider how it was trained, and frame your prompt to line up with as much appropriate material as possible, while ensuring specific details guide it away from misaligned material.
Narrowing open ended inputs
Summarizing and classifying information from freeform input into known options or into a standard format are great ways to use LLMs. Because most of the desired output is part of the input, e.g. direction on format, options, and examples, the model does not need to "think outside the box".
This is huge for products that can better set defaults out of the box, infer and extract relevant details without knowing the source format, and supporting more integrations with less code.
Fill in the blanks
Before Chat took over, LLMs exposed completion APIs that required structuring prompts as a narrative which the LLM could simply pick up where you left off. This is how most training data is structured and results in fewer 'connections' to line up, leading to more accurate results.
While Chat models drastically improve the output for less structured inputs, the more direct we can make inference, the more predictable LLMs will be.
Apply a specific methodology
LLMs excel at applying well documented approaches to a freeform context or problem, given how many examples would be in their training. These are also likely to draw in higher quality influences as they would be used in academic and professional contexts.
Put it in character
If there's a persona or role you can put your LLM in that aligns with your prompt, you'll benefit from the experiences of similar characters that were part of training. This will reduce how prescriptive you need to be about how the model should behave.
Risky uses of LLM tech
Multi-step processes known in advance
When possible, break apart complex flows that perform multiple steps - i.e. extracting details from a resume then evaluating those details for a role.
While convenient, uses like this will behave inconsistently and be difficult to debug. The model must predict the combined outcome of two activities which will be less refined than each activity individually.
By breaking it apart, you end up with more observable, testable and working code.
Unclear desired outcome
LLMs have no agendas of their own, so unless you give them a target or direction they will likely not produce consistant enough outputs for you.